A Hybrid Model of Novices' Performance on a Simulated CIC Task
Eric Scott and Sandra P. Marshall
ABSTRACT
This report is a description of work done under ONR Grant N00014-95-1-0237, "Learning in tactical Decision-Making Situations: A Hybrid Model of Schema Development." It is an excerpt from a technical report soon to be released. During the three-year period of the study, we created a testable environment in which to study the development of schemas of tactical decision making, we carried out a series of experiments with human subjects (novices) to investigate their performance in the environment, and we developed a hybrid cognitive model that predicts at a detailed level the behavior of individuals working in the environment.
In this report we focus on the implementation of the hybrid cognitive model. The model is implemented in LISP, with the bulk of the rule-based activity developed under the ACT-R architecture. Both declarative knowledge and procedural knowledge are organized around a set of schemas for commonsense knowledge that novices are presumed to have brought to the task. Judgments about which objects in the environment to attend to are modeled with the help of a neural network.
Input to the model consisted of recorded states of the subject's task, together with the responses made by the subject. Modeling consisted of constructing a deterministic system in the hybrid architecture and selectively constraining certain productions not to fire when to do so would be inconsistent with the recorded behavior of the subject. The accuracy of the model is measured against the number of times such constraints are required.
INTRODUCTION
This report describes a computer model of the behavior of novices using a simulation of the Combat Information Center (CIC) employed aboard an Aegis cruiser. The task we are modeling requires that the subject put himself in the place of a ship's captain in various simulated scenarios which take place in the Persian Gulf, off the Korean coast, and off the coast of Cuba. The subject's task in general is to monitor the situation at hand, to defend his ship and those of his allies, but to avoid unnecessary conflict, including conflict with civilian non-combatants. The general task is open-ended and without direct, objective feedback.
The computer model uses a hybrid architecture with both symbolic and sub-symbolic elements, and organizes its knowledge base around a schema-based paradigm. The general schema theory derives from the theory originally developed for the domain of problem solving (Marshall, 1995) and recently extended to tactical decision making (Marshall, McAllister, & Christensen, 1997). The model takes as input protocols collected from human subjects, including eye tracking data. We employ a novel method of aligning the model's behavior to the subject's by employing what we call the 'zig-zag' method.
OVERVIEW OF THE PROJECT
A Usable Testing Environment: The CIC Task
The tactical decision making required of Navy officers in a ship's Combat Information Center (CIC) is the underlying basis of the research undertaken here. A computer simulation of the CIC setting, called the CIC Task, was developed for use in ONR's Hybrid Architecture Research Program.
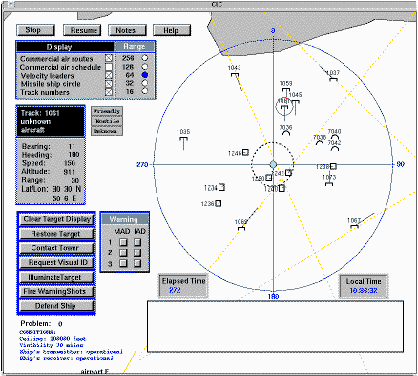
This simulation is a highly simplified representation of the computer displays available to a Commanding Officer or Tactical Action Officer in the CIC. Figure 1 features a snapshot of a typical screen. Prominent is a map of the geographical region, encompassed by a circle whose center indicates the position of the subject's own ship. Within the circle are icons of varying shapes indicating the position and velocity of radar tracks detected in the area. The shape of each icon indicates whether the vessel is an aircraft, a surface vessel, or a submarine. For each track there is a line extending outward whose direction indicates the direction of motion and whose length reflects the velocity of the vessel. The subject has control over several aspects of the display.
For a number of the displays, it is necessary that the subject first select a particular target by moving the mouse cursor to it and clicking to select it. This procedure is called hooking a track. Clicking on a track icon hooks that target, causing a small circle to surround it. The subject can issue commands that involve the hooked track by pushing one of the buttons in the panel at the lower left hand side of the screen (which contains a list of the various actions he might take with respect to the target), or one of the smaller buttons in the panel marked 'Warning'. He can remove the track from the screen (presumably if the track is judged to be clutter) or redisplay tracks so removed in reverse order of their removal. He can request that a civilian control tower indicate whether a commercial aircraft is known to be at the coordinates of the hooked track ('Contact Tower'); he may ‘illuminate’ a track, which in real-world situations enables the ship accurately to target the track and communicates to that track’s crew the threatening fact that the track is being targeted. He may ‘fire warning shots’ or actually fire on the target by pressing the ‘defend ship’ button.
The panel marked 'Warning' contains a small matrix of buttons whose rows correspond to the three levels of warning, and whose columns reflect a choice of two frequencies. The levels of warnings range from a polite request that the track identify itself and state its intentions to a direct threat that the target will be fired upon if it does not change course. The two frequencies are essentially military and civilan. The fact that the target may be tuned to one of two frequencies is an added complication to the task. In the simulation, some tracks will respond if warned on a frequency to which they are tuned, and some tracks will ignore all warnings, no matter what the frequency.
Figure 1. The main display screen of the CIC task.
The Current Data Set
In light of the results of some preliminary experiments, we developed an experimental paradigm and set of three scenarios, with the general themes from the Persian Gulf, Cuba, and the coast of Korea. These scenarios were each 15 minutes in length and contained common elements that allow comparison of individual performance across scenarios. In addition, we created briefings for each scenario to set the stage for the subjects, and we developed a short on-line review of the CIC display.
Subjects were instructed intensively in the operation of the CIC system through an on-peration of the CIC system through an on-line tutorial. Eye tracking data was taken for each subject in reading these instructions, providing the basis for analyzing a possible relationship between the subject's patterns of attention during training and subsequent performance on the task.
ARCHITECTURE OF THE MODEL
The overall structure of the model can be explained using the metaphor of a movie projector (fig 2). Each batch of input is a sequence of events collected from a subject's performance of a scenario, time-stamped and processed in temporal order (rather like a frame of film). Each event is projected onto the 'screen' which represents the current state of the situation. This state has two aspects: an objective aspect, which is a representation of the status of all objects on the CIC's monitor, and a subjective aspect, which is the model of what the subject is experiencing at the time. As an example of the differences between these two aspects, the objective model would process a "warned target replies" event by changing its representation of the text box, but the subjective model would only encode the contents of that message if the subject were observed to have examined the text box at the appropriate time. The subjective representation is also informed by the contents of the 'long-term memory', the subject model.
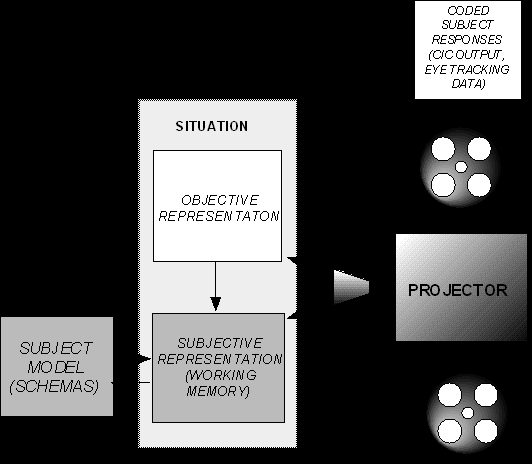
Figure 2. The structure of the program which drives the model explained with the metaphor of a movie projector.
Scenario Input
It is very useful to have exact information about what an individual notices at any point in time as well as his responses to it. In order to obtain this additional information, we have incorporated eye tracking into our experimental paradigm. The eye movement data of interest are the scan patterns across various regions of the display as well as the frequency and duration of fixations in the regions.
The fundamental data provided to the model centers on scenario details produced by the CIC simulator. Each scenario was analyzed at eight-second intervals to determine necessary information about the status of each track in the scenario. Also necessary as input to the model are changes made to the display by the current subject. The output of the CIC is then elaborated by human experts in conjunction with eye tracking data. Such analysis can encode judgments such as whether tracks were traveling in formation, whether it is likely that the subject was noticing a specific track during a critical part of the scenario and the information that a subject looked at text messages when they appeared on the screen.
Situation and Subject Models
The projector module in the system (see Figure 2) takes each event in the time line and makes changes to the objective representation, which tracks the status of each important entity on the screen. It also coordinates the execution of the ACT-R stack, which serves as the subjective representation of the subject's immediate experience (i.e., the model of working memory).
The subjective representation is informed both by the objective screen representation and by ACT-R constructions which are intended to model the pertinent parts of the subject's long-term memory. Up to the present, most of the behaviors modeled in ACT-R have tended to revolve around precise models of relatively small-scale tasks such as list memorization Anderson (1993), Since the behavior being modeled here is a coarser-grained model of much more complex behavior, we rely on another organizing principal overlayed upon those provided by the ACT-R architecture. Here the central organizing principal is that of a schema.
The model of schema development that is the focus of this research builds directly on the schema models of problem solving described in Schemas in Problem Solving (Marshall 1995), and on the schema models of decision making currently being developed under ONR Grant No. N00014-93-1-0525 in relation to the TADMUS Program (Marshall et al, 1996). The model is a hybrid integration of a neural network for pattern recognition and a rule-based components for step-by-step reasoning.
The subjects we are modeling are novices to tactical decision making. Nevertheless, it is assumed that they bring considerable expertise (and schemas) from commonsense domains to the CIC task. The pertinent schemas that are applied to the CIC task involve asking and answering questions, selecting buttons on the screen and observing the consequences, understanding threats and avoidance responses, and carrying out actions of self defense. In building the knowledge base that makes up the initial state of the model, structures and rules have been built using the ACT-R architecture to model these commonsense schemas.
To represent the performance and learning of a specific subject, the model requires input data from the subject's reading of the task instructions as well as input data resulting from the subject's performance during a scenario. The instruction input data consists of several eye tracking variables that provide information about the way the subject responded to the several pages of instructions. Included here are fixations, scan patterns, and total dwell times. The first subjects modeled were chosen in part because their behavior in reading the instructions suggested that they understood the task completely.
For the domain of tactical decision making, a schema is defined as a coordinated set of knowledge which an expert might be said to possess, and as such it is characterized by behavior and inferences which are quick and smooth. Such expert knowledge can be broken down into four types: identification, elaboration, planning, and execution (Marshall, 1995).
Identification knowledge refers to an expert's ability to attend to the important parts of his current situation and to ignore the unimportant parts. This recognition process is essentially the result of a sub-symbolic process and is not subject to expression as a set of definable rules. For example a study of Navy officers shows that they attend closely to some tracks on the radar screen and ignore others altogether, in a way which can be modelled accurately by a neural network (Marshall et al., 1996).
The other three categories of knowledge are thought to be subject to expression at the symbolic level. Elaboration knowledge refers to an expert's ability to assess the deeper nature of the things he identifies in the current situation and to have a set of expectations as to how these things will behave based on his or her experience with similar entities in the past. It also refers to experts' knowledge of how and when to find out more about that entity so as to gain a deeper understanding of it. For example, an expert might infer that a fast-moving track that is not identifiable as a commercial airline and that originates from a hostile country is likely to be a MIG. From there, the expert would make additional assumptions about the likely behavior of the track.
Planning knowledge refers to the ability of the expert to form expectations, properly sequence goals and subgoals, anticipate obstacles, and recover from failures. For example, in the CIC task it is neple, in the CIC task it is necessary to illuminate a target in order to fire upon it with accuracy.
Execution knowledge refers to an ability to apply the available operators entailed in his plan. This is the kind of knowledge which seems to take place ‘without thinking about it’. Examples of this kind of knowledge which apply to the CIC task are those that involve pushing buttons, making mouse clicks, and reading text.
This theory has influenced our model in the following ways. The process of selecting new tracks to which attention is shifted is aided by the action of a neural net. Elaboration of each important track is conceived of as the first step in the model's approach to dealing with the track. Because the subject we are modeling is a novice, this is an area of knowledge which he is actively developing. The architecture of the model is driven largely by declarative representations of exemplars which may be thought of as plans constructed by the subject as he applies commonsense schemas to his understanding of the instructions. Execution knowledge in this task is largely a matter of clicking on buttons with a mouse, which is a somewhat trivial matter, but there are times when apparent acts of clumsiness on the part of the subject seem to excuse our model from replicating certain of his actions.
The ACT-R formalism prescribes a dichotomy between declarative and procedural knowledge. Schemas contain both types of knowledge. Each schema revolves around one or more hand-coded exemplars (following Bareiss 1989), adapted to represent plans the subject would compose in light of appropriate schemas when reading the instructions.
Figure 3 serves as an example. This figure represents a declarative exemplar which the subject is presumed to have formed after reading in the instructions that it is possible to ask a vessel directly to identify itself. The example contains two event kernels, one which is the self-id event itself, and the other which is an event of compliance to a request.
The self-id event node has attached to it three roles: the answerer, which is the party identifying itself, the answer, which is the message produced by the answerer, and the fact, which is the identity of the answerer. There are two outcomes encoded for the self-id event: one is that the answer is in the text box, another is that the answer is about the fact. Note that the fillers of the answerer and answer roles are left unfilled, as is the object identified by the fact. Certainly, this representation is a kind of shorthand, with only the details included in it which are necessary to drive the model. A more detailed elaboration might assign the text box to the role of medium, include an asker, etc.
The compliance event encodes two roles, the complier and the request. The request is filled with the representation of the self id event described above, and the complier is encoded as its answerer role. The self-id event is also encoded as the outcome of the compliance. A condition of the outcome is that the complier know about the request. This condition then serves as the cue in the model to look for other exemplars which encode outcomes that cause people to know about such requests.
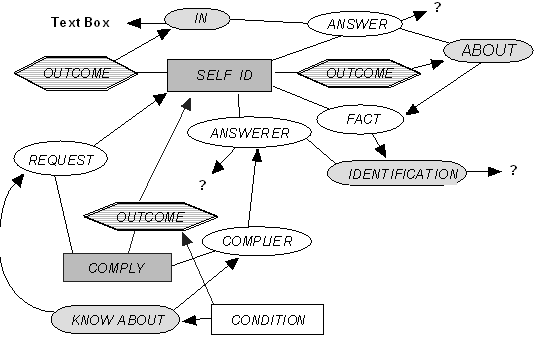
Figure 3. A declarative exemplar associated with the schema for asking tracks to identify themselves.
Our present approach attempted to use a minimal set of types for constructing exemplars in declarative memory, with types for relations, events, roles, outcomes, and conditions. In addition to these, we found it necessary to develop a more elaborate set of goal-DMEs. A brief discussion of each follows
1) The relation type. This was originally complemented by an ‘Attribute’ type, but was re-implemented in light of Langacker’s (1987) approach to knowledge representation, which speaks in terms of relations with trajectors and (often) landmarks.
2) The event type expresses a single unified collection of relations which are associated with a given type of episode. Efforts were made to make the event type as simple as possible, and has only the slot for the name of the event. The reasoning behind this was to enable using cause-event goals as event nodes to serve as the kernels around which roles and outcomes served to flesh out the particulars of each type of event
3) The Role type expresses the existence of what have been called ‘aspectuals’ (cf. Willensky 1991), ‘elaboration sites’ (cf. Langacker 1987), etc.; they serve as the place-holders for entitites which charactistically have certain attributes, and have certain relationships to the fillers of other roles during the kinds of events being defined. Each role has a slot pointing to the event to which the role belongs, a slot for a label, and a slot for the eventual filler of the role. An advantage to having roles as an explicit primitive (rather than a slot in a more elaborate set of event types) is that it provides the opportunity for using publicly available role nodes as indexes to the entire schema. One aspect of elaboration knowledge involves recognizing the appropriate filler for each role when applying a schema to a situation.
4) The Outcome type is intended to express a resulting state which typcially holds for a given type of event. It has slots which point between an event kernel, and the representation of some relation or event that is asserted to hold true after the event has come to pass. The relation in turn applies to or between one or more roles which are ascribed to the event. Outcomes serve as indexes for their exemplars, and associated schemas. If the model has a goal to cause some person to know about some fact, for example, an outcome that links the ask-answer event to that relation may be considered as a means to that end.
5) The condition type links outcomes with some other attribute or relation which applies between members of the schema. Its purpose is to express the conditions which enable the outcome to be produced, and perhaps motivate the next round in subgoaling.
Because in ACT-R goals are also declarative structures, the most important goal types have to do with causing events, causing attributes, causing relations, filling roles, and checking outcomes. The fact that goals are declarative structures allows us to create an episodic memory in a straightforward manner by including pointers between goals, subgoals, and sibling goals.
The procedural component implements the pattern matching aspect of applying a schema to the situation at hand, using declarative exemplars as prototypes. There are productions which consider a particular outcome as a means of achieving particular goals (e.g., "if you want text about some track to appear in the text box, consider asking the bridge for a visual ID"), productions for disqualifying certain schemas (e.g. "if you're considering a visual ID, and the track is not in visual range, then stop considering it.") Another important class of productions consists of those which fit objects in the environment to roles (e.g. "if the note in the text box is from your crew, and is about track t, then that message is your answer").
How the Model Works
Modeling the subject consistg the subject consists of predicting and confirming each decision made (i.e., each button clicked) by the subject. All recorded subject actions are modeled with the following exceptions: instances where an action was taken twice in rapid succession; instances where a track was hooked and nothing else was done; changes in the screen display that do not pertain to individual tracks (e.g., range of the radar display, air lanes); verbal communications with the experimenter conducting the study; and occasional anomalies which defy explanation (e.g. one instance where the subject hooked a track and issued a warning just as the track was leaving the screen).
The approach to modeling used here differs from those in which the model is allowed to perform the task independently of the subject and then the actions of model and subject are aligned for comparison and evaluation (e.g., Ritter & Bibby, 1997; Card, Moran, & Newell, 1983). The task we are modeling is complex and dynamic with many possible actions. Over the course of a 15-minute scenario, the model could decide to take an action that the subject did not. This action changes the dynamics of the scenario, so that from that instance onward, the model and the subject no longer 'experience' the same scenario. Consequently, we opted to create a sequential modeling process in which we look at each step sequentially and determine the success or failure at that point of the model in predicting the subject's performance, using what we call a 'zig-zag' technique (described in more detail below). This is a more difficult and time-consuming modeling process than the alternative. At this point, we have modeled completely every action taken by two subjects for two 15-minute scenarios. We have also selected critical and parallel instances in all three scenarios and looked at the model's success in predicting several additional subjects performance across the scenarios.
Events in the time line are processed one at a time, updating the objective representation of the screen. Each event is an update of some screen object, including any actions taken by the subject on that entity. Part of this input includes an indication of whether that screen object was noticed during that interval by the subject. Any object judged to have been noticed has its subjective representation updated as well. This might involve encoding new memory elements, or it might involve retrieving the value previously encoded, and updating it as needed.
Our model of the subject's attention starts by attaining a neural net response of noticeability to the profile of each visible track. Tracks are placed in a queue in decreasing order of the strength of this response. Tracks which are subsequently hooked and interacted with are selected from this queue by the operation of the ACT-R production system.
ACT-R operates through a goal stack whose dynamics are implemented with our model as follows. A single event- this session is always present at the base of the stack. As new tracks are selected to be dealt with, a deal with track goal is pushed on the session goal. On top of that, one of three types of subgoals may be pushed: elaborate track, divert track, and destroy track. By way of illustration, the elaborate track goal is satisfied when it has reliably identified the track, and will repetitively launch cause me to know about track goals until it does so, or gives up. This in turn launches cause read event goals, and since a condition of the outcome of the reading schema is that messages about the topic appear in the text box, this motivates goals to cause text to appear in the text box, which motivate either a cause self id event goal or a cause ask third party event goal, and so on. Alongside this basic means-ends process are collateral goals to preview the goal before committing to causing these events, to fill unfilled roles, and to check outcomes to see if the desired result has been effected.
The exemplars described above serve as the basis for organizing new goals, as illustrated in Figure 4. Given that the model has already set a subgoal to cause a message to be about the identification of track 1061, there is a production attatched to the self-identification schema (see Figure 3) which says in effect "if your goal is to get the identity of some entity, consider asking that entity directly', which after being considered and accepted then causes the subgoal cause-event to be pushed on the stack which uses the self-id node in the exemplar to fill the prototype slot in the goal. The roles associated with the exemplar are copied, with the 'event' slot of each new role object filled with the new 'cause-event' goal. The result is a kind of 'clone' of the exemplar. Elements of procedural memory serve to recognize which memory elements can fill unfilled roles.
Procedural memory also determines that since 'self-id' is the outcome of the 'compliance' node, that a goal to cause-event is next pushed on the stack, with 'compliance' serving as its prototype, and its analogous roles cloned in turn, and filled where possible. From here, a goal would be pushed to cause the complier to know about request, where productions associated with different schemas would have to recognize their applicability to the role and fire in turn.
This process results in a fairly tall stack, which is consitant with the picture of a novice piecing together goals from several schemas to explore the new task. We would expect one of the effects the process of learning a new schema to be a tendency toward shorter stacks.
Initial plans for implementing the architecture assumed that there would be a number of general purpose productions which applied to all schemas and organized the overall structure of the goal stack ("If you have a goal to cause some relationship and there is some outcome that points to a relationship that matches, then use the exemplar with that outcome"). It became clear, however, that such productions were long and brittle, and subtle variations on the same production would tend to multiply in the process of writing the model. Eventually we came around to the practice of giving each schema a similar anatomy of productions that are unique to that schema and which perform the function of knowing how each schema fits into the big picture (e.g., "If you want text about some track to appear in the text box, consider asking the tower about the track.").
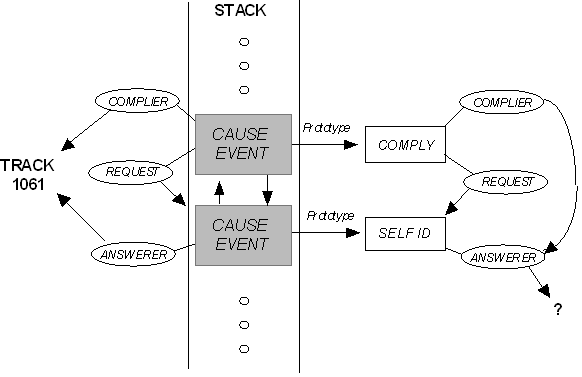
Figure 4. An illustration of how roles attached to the exemplar in Figure 3 are copied, applied to the analogous cause-event goals, and filled as they propogate up the ACT-R stack.
Handling Interruptions and Shifts in Attention
ACT-R has a mechanism for single inheritance, and each goal type is descended from a parent which has a slot for indicating the result of the goal. The main values that can be assigned to this slot are success, failure, and pending. This inheritance mechanism allows productions which apply generally to all goals to be used in cases where the subject's attention shifts between tracks (which with some subjects happens often). When this happens, all goals above the 'this session' goal on the stack are marked pending and popped off the stack. When on occasion attention eventually shifts back to the interrupted track, each of the pending goals is pushed back on the stack and the process resumes.
Attention can shift to another track either at the top of the stack, at times when the model is waiting for something to happen (such as text to appear in a text box), or at the bottom of the stack when a track has just been dealt with, and the only goal on the stack is 'this session'. When this happens a goal is launched to find the next active track. This is accomplished with the aid of a neural network model.
The neural network models the extent to which the subject notices specific tracks. During the course of the scenario, the tracks that are available on the display are recorded for each 8-12 second time period and updates are included in the time line. For each track, a set of twelve features is encoded (range, speed, inboundedness, etc.). These binary features form a profile of the track and serve as the input to the network. From the eye-tracking data for a particular subject, we can determine which of these tracks were observed by the subject during any specific time segment. This information is the desired output of the model. The neural network that performs the recognition of noticing tracks has 12 input units, three hidden units, and two output units.
For each subject, a network is trained using back propagation to respond as the subject would over the entire population of 63 distinct profiles available during all scenarios. The resulting pattern of weights is then fixed and used throughout the simulation of the subject's performance. Whenever the network is accessed, these weights determine its response.
Finding the next track to be given active attention by the ACT-R model is done as follows. The set of available tracks is determined by presence or absence on the screen, as indicated by the objective representation. All tracks that are present are potential targets to be noticed. The profiles of all eligible tracks are input to the neural network model, which estimates the degree of "noticeability" for each one. All eligible tracks are then considered by the ACT-R productions to determine which one should be selected for attention. For purposes of our first application, we used productions which discounted surface ships, aircraft which were not inbound, and tracks which had been dealt with before, which yielded about 47% accuracy in predicting which track would be hooked.
The Zigzag Method
When dealing with the problem of letting the model run independently of the subject, a problem can arise, particularly in situations which are quite dynamic: If our model has predicted a particular course of action, and that action would lead to a significant change in the stimulus, then from that point on subject and model are dealing with different stimuli and comparisons between the two become difficult. To deal with this problem, we adopt the convention of making the last condition in certain productions a call to a Boolean function called 'zig?', with arguments identifying the production and giving access to the state of the model. In other words productions would sometimes take the form
If <condition 1> and <condition 2> ... and (zig? <this production> <this context>) then ...
If zig? returned true then the production would instantiate, otherwise it would be said to 'zag', and would not fire even if the substance of its left hand side and its weight entitled it to do so. Control of the model then would pass to the next strongest production. Modeling a subject's behavior on a particular scenario would then consist partially in declaring points where productions should zag. This would serve to keep the model on track. Keeping track of when and how often each production zagged then provides an indication of which productions stand for the most improvement. The vast majority of productions are not zaggable, so the set of productions which need to be so constructed in a sense form a set of parameters which can be adjusted within the model.
The model was initially developed based on the performance of one subject who worked through the first set of CIC scenarios which will be discussed under the heading 'Preliminary Work' in the forthcoming technical report. This early model required a total of 234 productions to predict and confirm each of the subject's actions. The model was then applied to the performance of a second subject who worked through one of the core set of three scenarios developed later. To predict and confirm each action of this subject, 104 productions had to be added, for a total of 338 productions. Of this total, 32 rules were made zaggable in order to make the model fit the behavior of the subject. It is expected that future work with an automated zig-zag process will yield data for many more subjects, and enable us to discuss the accuracy of the model in detail.
REFERENCES
Anderson, J. (1993). Rules of the Mind. Hillsdale, NJ: Erlbaum.
Bareiss, R (1989) Exemplar Based Knowledge Aquisition. A Unified Approach to Concept Representation, Classification, and Learning. Boston: Acedemic Press.
Card, S. K., Moran, T. P., Newell, A. (1983). The Psychology of Human-Computer Interaction. Hillsdale, NJ: Erlbaum.
Langacker, R.W. (1987) Foundations of Cognitive Grammar. Stanford: Stanford University Press.
Leake, D.B., ed. (1996) Case-Based Reasoning. Experiences, Lessons, and Future Directions. Menlo Park: AAAI Press/ The MIT Press.
Marshall, S. P. (1995). Schemas in Problem Solving. New York: CambridgeUniversity Press.
Marshall, Christensen, and McAllister (1997) 1996 Command and Control Research & Technology Symposium. Center for Advanced Concepts and Technology.
Ritter, F. E., Bibby, P.A. (1997). Modeling Learning as it Happens in a Diagrammatic Reasoning Task. Technical Report No. 45, ESRC Centre for Research in Development, Instruction, and Training.
Schank, R.C. (1982). Dynamic Memory; A theory of reminding and learning in computers and people. Cambridge: Cambridge University Press.
Sonalysts, Inc. (1995). TADMUS EXPERIMENT: Decision-Making Evaluation Facility for Tactical Teams (DEFTT) Scenario Documentation. Report prepared for Naval Command, Control & Ocean Surveillance Center, San Diego, April 1995.